PL and Static Analysis
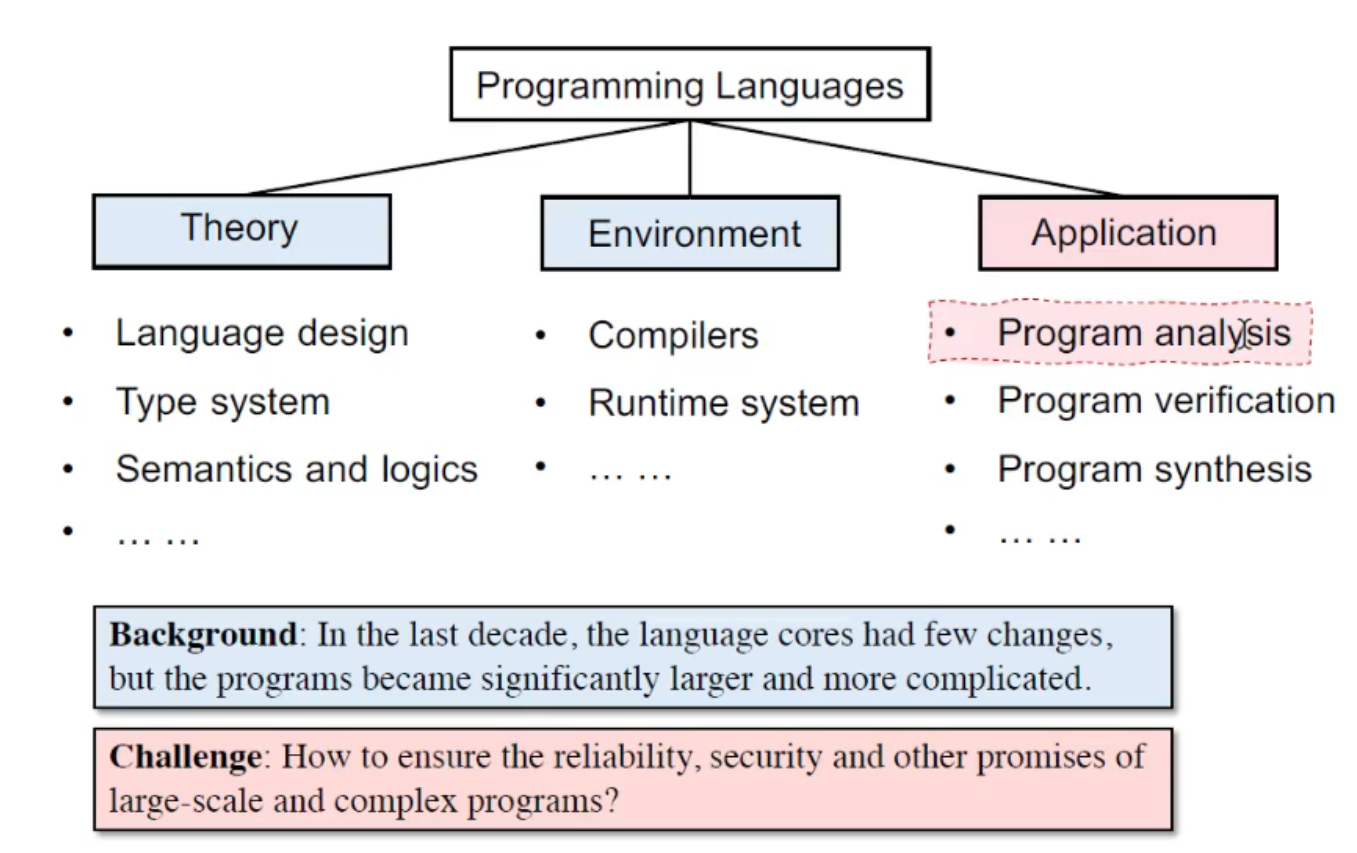
虽然语言的内核(core)没变——还是 imperative, functional and logical 三大类,但是用这些语言编写的程序愈发地庞大、业务逻辑愈发地复杂。因此,对巨型、复杂工程的分析越来越必要,就像上面所说的:
How to ensure the
- reliability
- never crash
- security
- never attacked
- and other promises
of large-scale and complex programs.
Why we Learn Static Analysis
对于程序可靠性
- 避免空指针解引用、内存泄漏,等等
对于程序安全性
- 避免私有信息泄露、注入攻击,等等
对于编译优化
- 清除 dead code、代码移动
对于程序理解
- 调用关系分析、类型推断
What is Static Analysis
Static analysis analyzes a program P to reason about its behaviors and determines whether it satisfies some properties before running P.
- Does P contain any private information leaks?
- Does P dereference any null pointers?
- Are all the cast operations in P safe?
- Can v1 and v2 in P point to the same memory location?
- Will certain assert statements in P fail?
- Is this piece of code in P dead (so that it could be eliminated)?
- ……
However, Rice's theorem states that all non-trivial semantic properties of programs are undecidable.
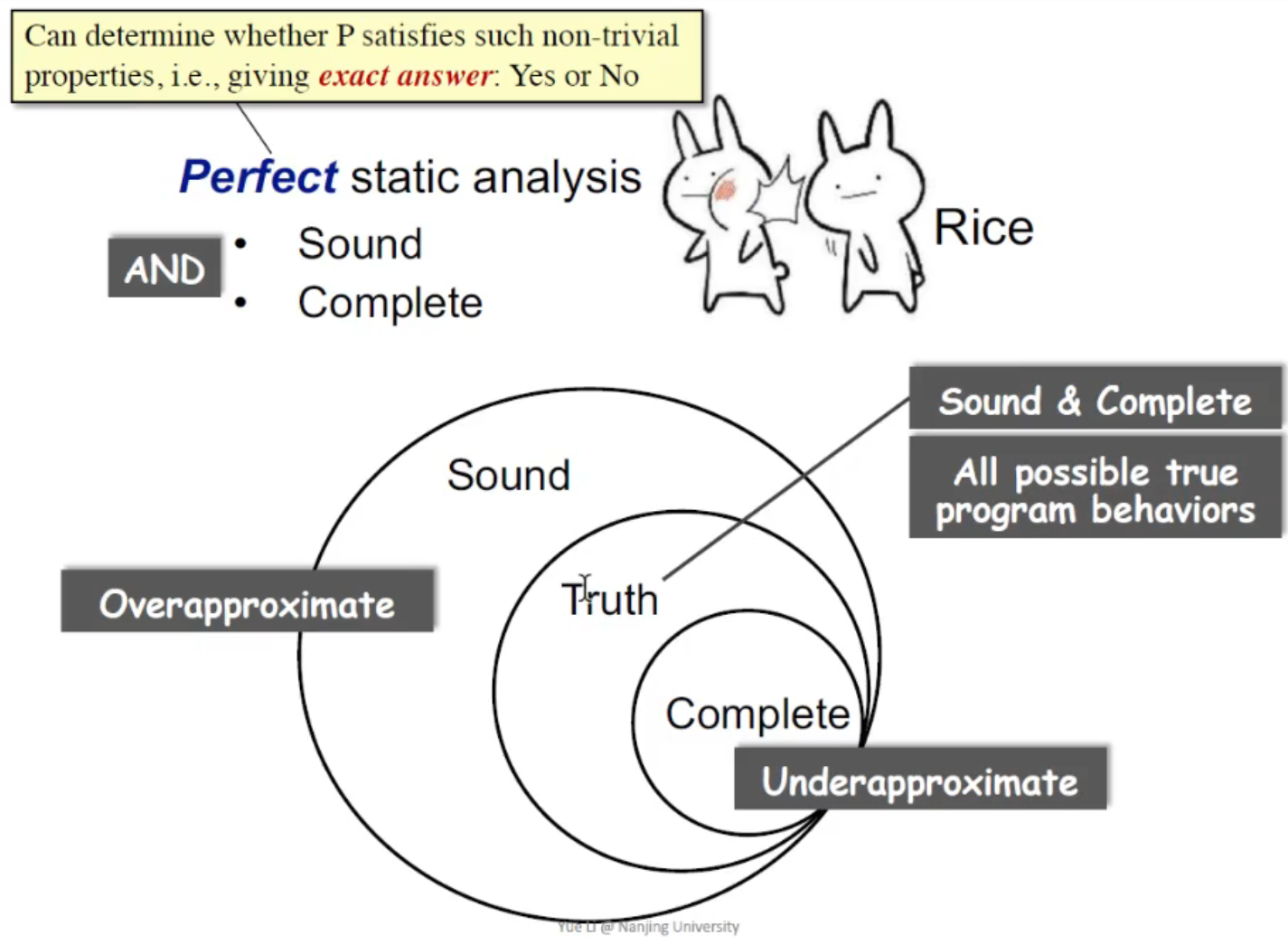
用另一种方法说:没有 perfect static analysis。Sound 和 Complete 里面,二选一。
Sound VS Complete
我们以“空指针解引用”为例:
- Sound 指的是不是空指针的,也报成了空指针。如果原来只有 10 个,你可能会抓到 20 个。误报 bug。
- Complete 指的是是空指针的,却没报成空指针。如果原来只有 10 个,你可能只抓到 5 个。漏报 bug。
一般情况下,我们都是 compromise completeness for soundness。我们宁愿误报,也不能够把本来有错的当成了没错。
这是因为,soundness is critical to compiler optimization, program verification, etc.
Static Analysis Features and Examples

有效的静态分析,就是在(几乎)满足 soundness 的前提下,实现分析精度和速度的平衡。
Two Words to Conclude Static Analysis: Abstraction + Over-Approximation
Abstraction
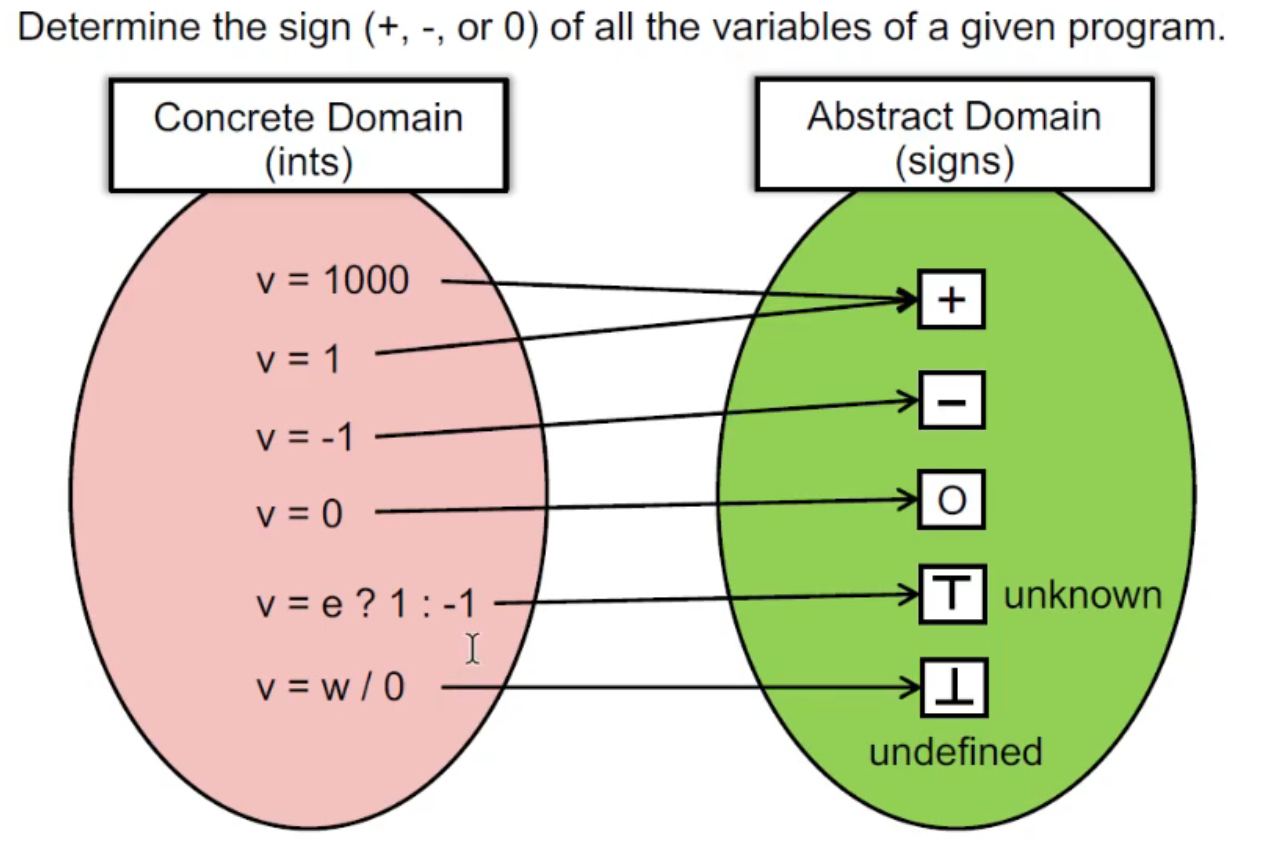
如图,由于
- 我们不知道
e是什么,因此v = e ? 1 : -1就是 ⊤ - 由于除零是未定义的,因此
v = w / 0就是 ⊥
Over-Approximation: Transfer Functions
我们对右侧的 abstract domain 定义一套运算法则 (i.e. transfer functions),such that 得到的结果一定是 sound 的,i.e. 顶多误报,不会漏报。
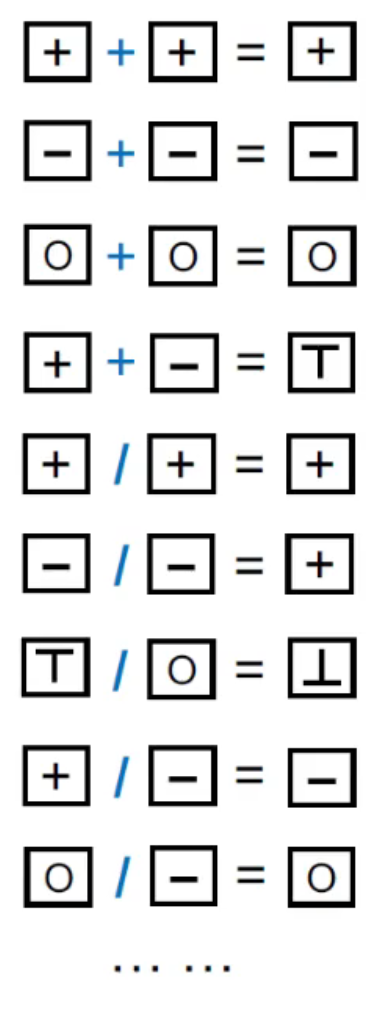
比如说:任何数除以 unknown,我们认为是 undefined,因为我们无法确定 unknown 是不是 0,依照不能漏报的原则,我们就认为它是 undefined
从而,对于我们下列的一个小 demo:
x = 10;
y = -1;
z = 0;
a = x + y; // pos + neg: unknown
b = z / y; // zero / neg: zero
c = a / b; // unknown / zero: undefined // This is a true positive
p = arr[y]; // indexing by neg: undefined // This is a true positive
q = arr[a]; // indexing by unknown: undefined // This is a false positive
Over-Approximation: Control Flow
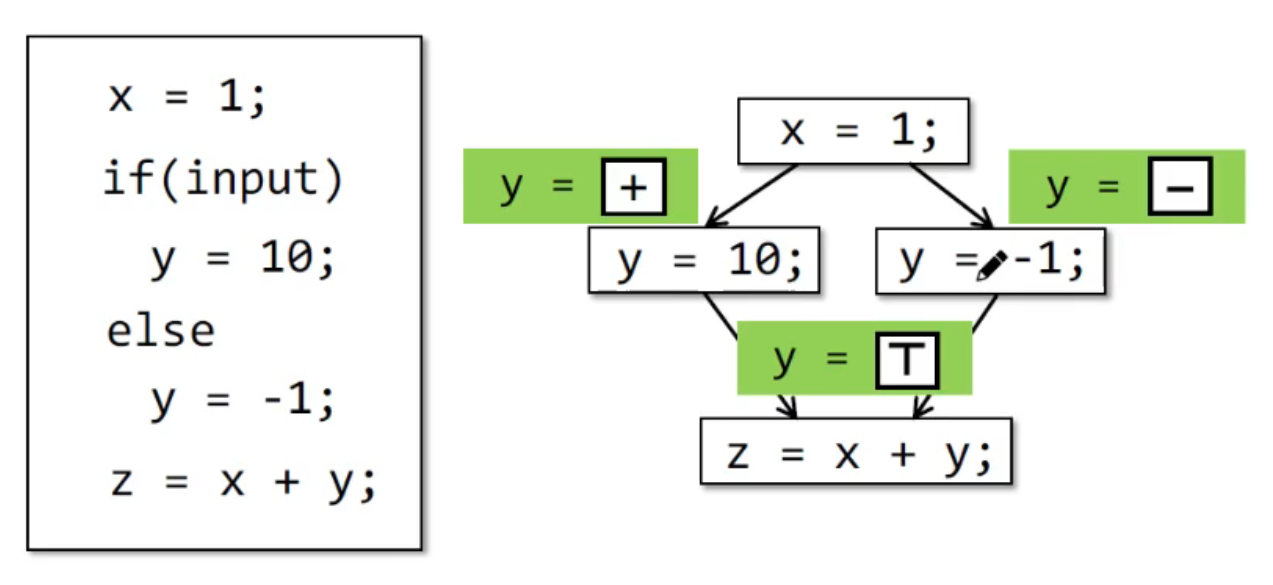
如图,我们在这个分支中,并没有考虑 input 具体的值,而是考虑了两个分支的情况。在实际的例子之中,由于分支可以指数爆炸,因此,我们肯定不能够分别考虑,而是需要进行图上的 flow merging。
Teaching Plan

如图,这个讲课顺序的设计体现了计算机科学中静态分析的基本理论和实践的逻辑顺序。以下是我对这个顺序的理解:
-
Introduction:引入主题,为后续的内容做准备。
-
Intermediate Representation:介绍中间表示,这是编译器和程序分析工具用来表示源代码的一种形式,为后续的分析做准备。
-
Data Flow Analysis-Applications:介绍数据流分析的应用,这是一种程序分析技术,用于收集关于程序在运行时可能采取的状态的信息。
-
Data Flow Analysis-Foundations(I & II):深入介绍数据流分析的基础知识,这是理解后续更复杂分析技术的基础。
-
Inter-procedural Analysis:介绍跨过程分析,这是一种更复杂的分析技术,需要理解数据流分析的基础。
-
CFL-Reachability and IFDS:介绍上下文无关语言可达性和间接函数调用数据流分析,这是两种更复杂的分析技术,需要理解跨过程分析的基础。
-
Soundness and Soundiness:介绍正确性和近似正确性,这是评估分析技术的重要标准。
-
Pointer Analysis-Foundations(I & II):深入介绍指针分析的基础知识,这是理解后续更复杂分析技术的基础。
-
Pointer Analysis-Context Sensitivity:介绍指针分析的上下文敏感性,这是一种更复杂的分析技术,需要理解指针分析的基础。
-
Modern Pointer Analysis:介绍现代指针分析技术,这是一种更复杂的分析技术,需要理解指针分析的基础。
-
Static Analysis for Security:介绍静态分析在安全领域的应用,这是一种更复杂的分析技术,需要理解前面所有的基础。
-
Datalog-Based Analysis:介绍基于Datalog的分析,这是一种更复杂的分析技术,需要理解前面所有的基础。
-
Abstract Interpretation:介绍抽象解释,这是一种更复杂的分析技术,需要理解前面所有的基础。
-
Course Summary:课程总结,回顾整个课程的内容。
这个顺序从基础概念开始,逐步引入更复杂的概念,每个新的概念都建立在前面的概念之上,这样可以帮助学生更好地理解和掌握静态分析的知识。