Lec 1:介绍
处理器发展趋势
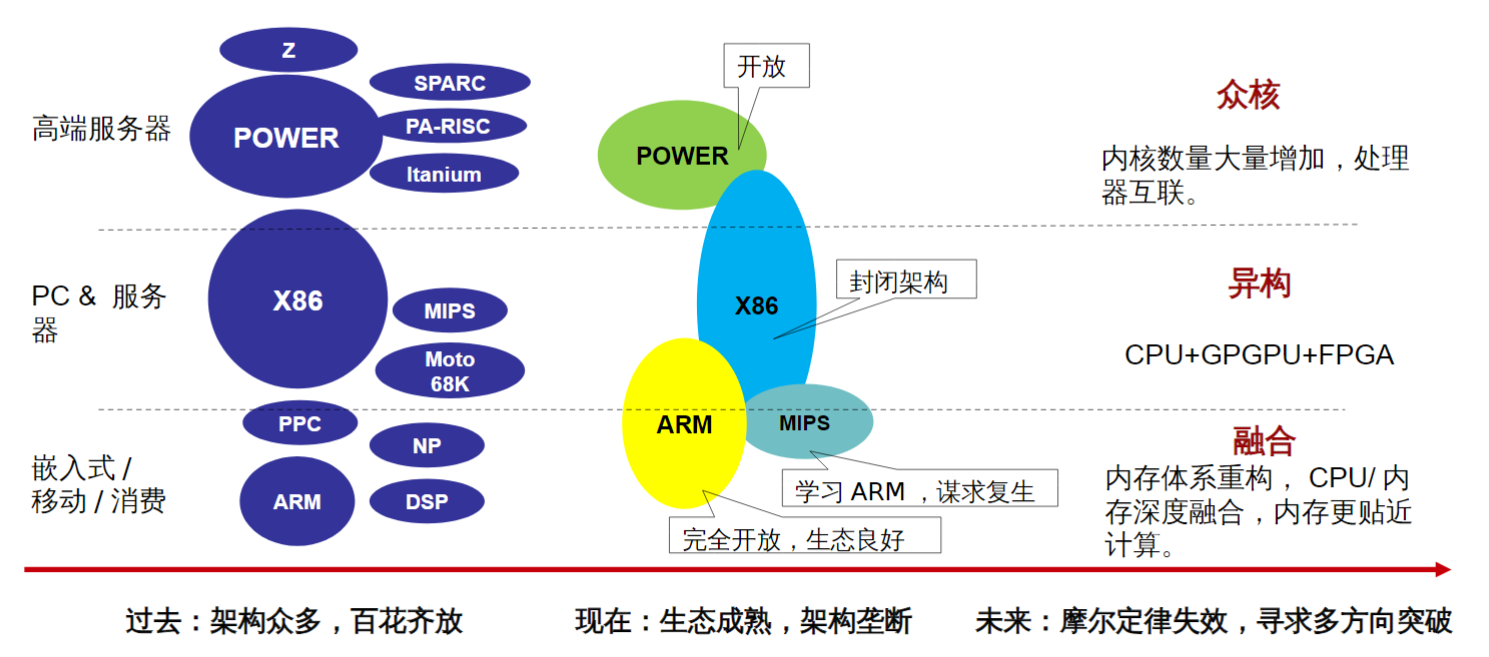
主流 CPU 发展路径
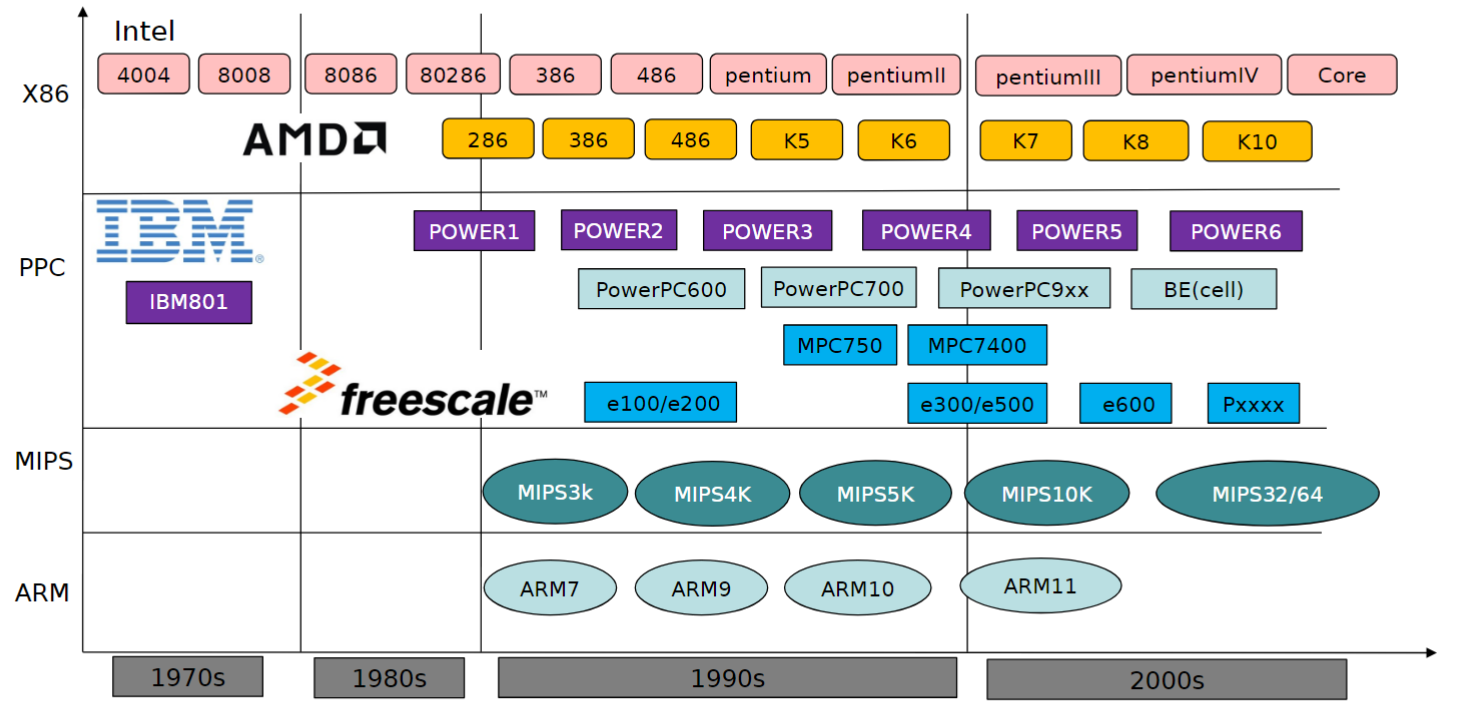
处理器芯片的发展趋势
- 工艺、主频遇到瓶颈后,开始通过增加核数的方式来提升性能;
- 芯片的物理尺寸有限制,不能无限制的增加;
- ARM 的众核横向扩展空间优势明显。
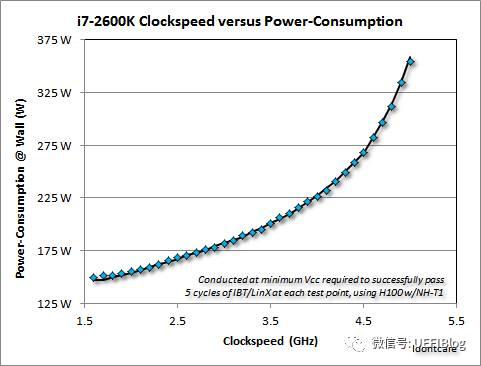
如上图,单核处理器的功耗远高于相同总计算能力的多核、众核处理器。因为功耗 \(P = CV^2f\),其中 \(C\) 是常数,\(V\) 是电压,\(f\) 是频率。但是,提高频率的同时,必须提高电压,从而保证门延迟不变。因此,\(P\) 在一定频率之上,就会和 \(f\) 呈近似 \(P = C'f^3\) 的关系,如下图:
ARM 处理器一览

一芯片多架构
在一个系统级芯片(SoC)上,有许多不同的指令集架构(ISA)。这些包括:
- 应用处理器(通常是ARM)
- 图形处理器
- 图像处理器
- 无线电数字信号处理器(DSP)
- 音频DSP
- 安全处理器
- 电源管理处理器
在一些SoC上,有超过十种不同的ISA,每种都有其独特的软件堆栈。
那么,为什么会有这么多不同的ISA呢?
- 应用处理器 (Application Processor) 的ISA对于加速器来说太大,不够灵活
- 应用处理器可以包括一个 CPU+GPU+内存+……,所以太大了
- 从而,我们只能从不同的公司购买 IP。其中,每个公司都用不同的 ISA
- 不同 IP,不同 ISA,之间如何交流?
- 工程师需要构建自己的ISA核心
- 为了自行设计用于交流的核心,工程师就需要一个开源的ISA: RISC-V
Great Ideas in Computer Architecture
TOC: 8 Great Ideas
- Design for Moore'sLaw(设计紧跟摩尔定律)
- Use Abstraction to Simplify Design(采用抽象简化设计)
- Make the Common Case Fast(加速大概率事件)
- Performance via Parallelism(通过并行提高性能)
- Performance via Pipelining(通过流水线提高性能)
- Performance via Prediction(通过预测提高性能)
- Hierarchy of Memories(存储器层次结构)
- Dependability via Redundancy(通过冗余提高可靠性)
1. Design for Moore's Law
设计不是一蹴而就的。一个芯片的设计,需要耗费很长的时间。
假设设计需要 5 年,而 IC 中的晶体管数量,在两年左右的时间,就可以翻倍。通过计算,5 年时间,晶体管数量可以翻 5.7 倍左右。
假设某一时刻的晶体管数量为 10 万,那么,5 年之后,就是 57 万。
如果你在 5 年前按照 10 万的标准设计,5 年后就会浪费性能,其他芯片的性能很容易超越你;如果按照 100 万来设计,那么芯片就无法立即投产。因此,必须估计准确。
2. Use Abstraction to Simplify Design
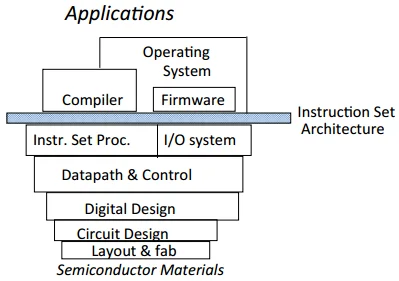
如图,就像计算机网络一样,
- 我们设计的目的是 applications
- 对于其中每一层的设计,只需要
- 使用下层的服务
- 完成本层的功能
- 为上层提供接口
3. Make the Common Case Fast
定量来说,我们有 Amdahl's Law $$ \newcommand{\sp}{\mathrm{Speedup}} \newcommand{\exec}{\mathrm{ExecTime}} \newcommand{\fr}{\mathrm{Fraction}} \begin{aligned} \sp_{enhanced} &= \frac{\exec_{enhanced, old}} {\exec_{enhanced, new}}\ \sp_{overall} &= \frac {\exec_{old}} {\exec_{new}} = \frac 1 {1-\fr_{enhanced} + \frac {\fr_{enhanced}} {\sp_{enhanced}}} \end{aligned} $$ 因此,对于 common case,\(\fr_{enhanced}\) 比较大,因此,只需要比较小的 \(\sp_{enhanced}\) 就可以使得 \(\sp_{overall}\) 较大。
设计时,一定要考虑哪一部分是 common case。
4. Performance via Parellel
采用并行的方式,我们可以将各个微处理器的芯片的性能进行叠加。
5. Performance via Pipeline
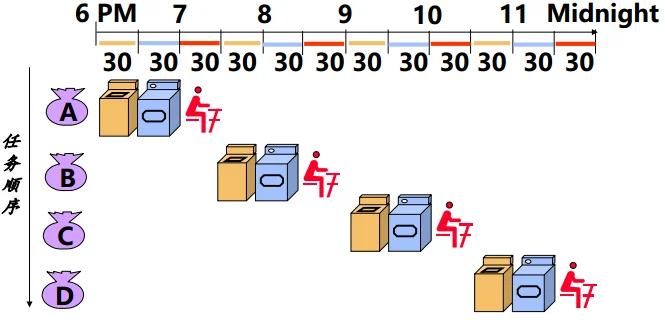
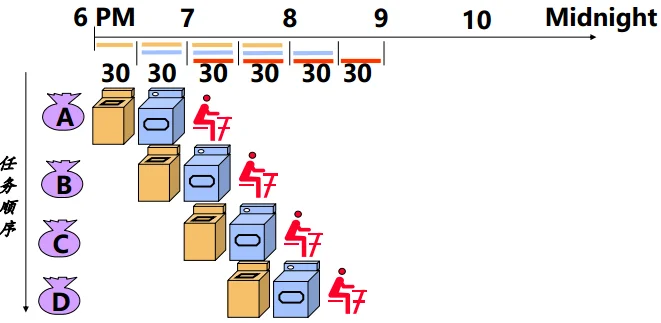
左图是非流水线的方式,而右图是流水线的方式。
不难发现,当任务足够多时,两种方式的每个任务平均处理时间为: $$ \begin{aligned} \exec_{left} &= \sum_i \exec_{i}\ \exec_{right} &= \max_i(\exec_i) \end{aligned} $$
6-8
容易理解
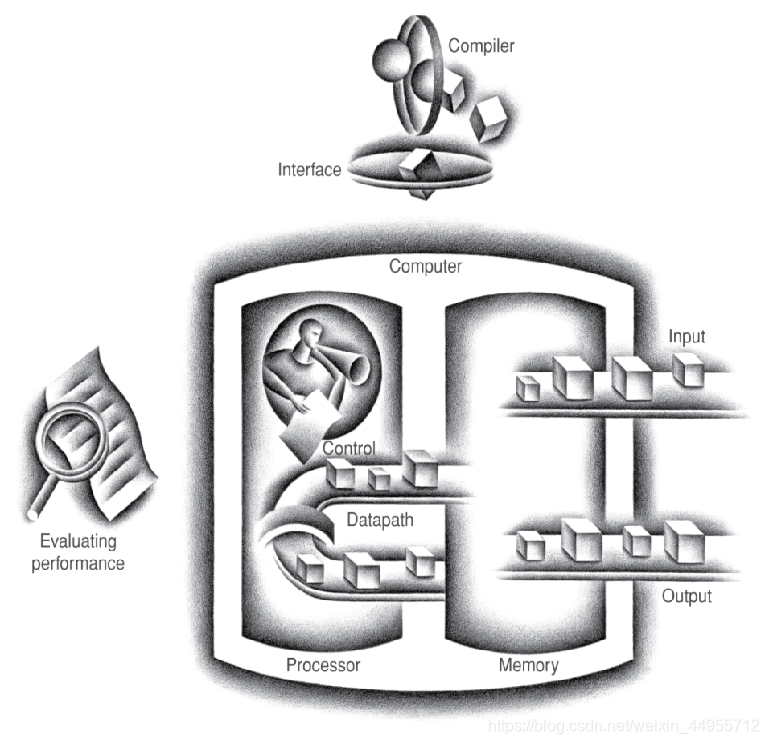
Computer Organization
注意:
- 由于写编译器的人,必须懂硬件(比如针对流水线等特性进行优化),所以编译器常常算做系统软件。
- Firmware (固件) 的制造方法,就是将数据烧到 ROM 里面,因此算作软件和硬件的结合。
- 设计多时钟周期 CPU 的时候,一条机器指令,是通过多个所谓 microinstruction (微指令) 共同完成的。我们会将 microinstruction 预先“烧”到 ROM 里去。
- 软件中,对于非常看重性能的功能,可以将微程序烧到 ROM 里去,以后需要调用这个功能的时候,就去 fetch 这个 ROM
Program Execution
以下是各种语言的流程:
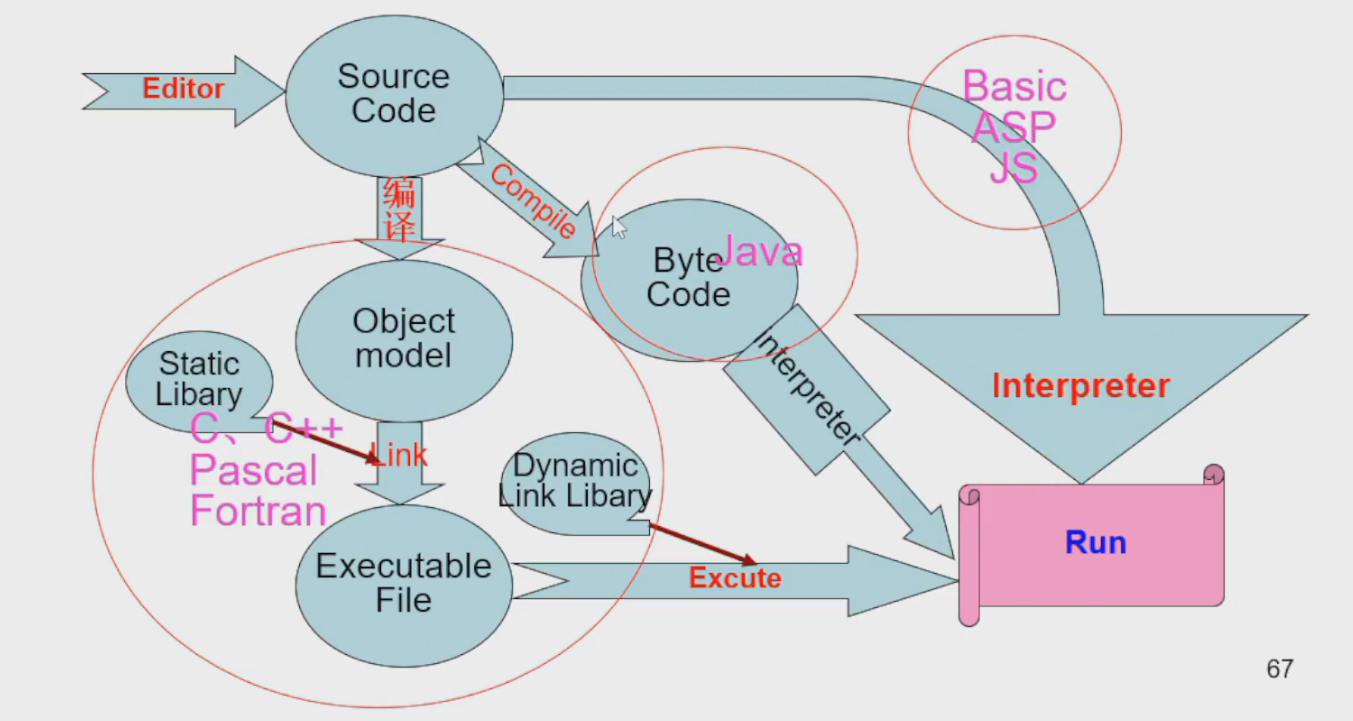
以下是 C/C++ 的流程:
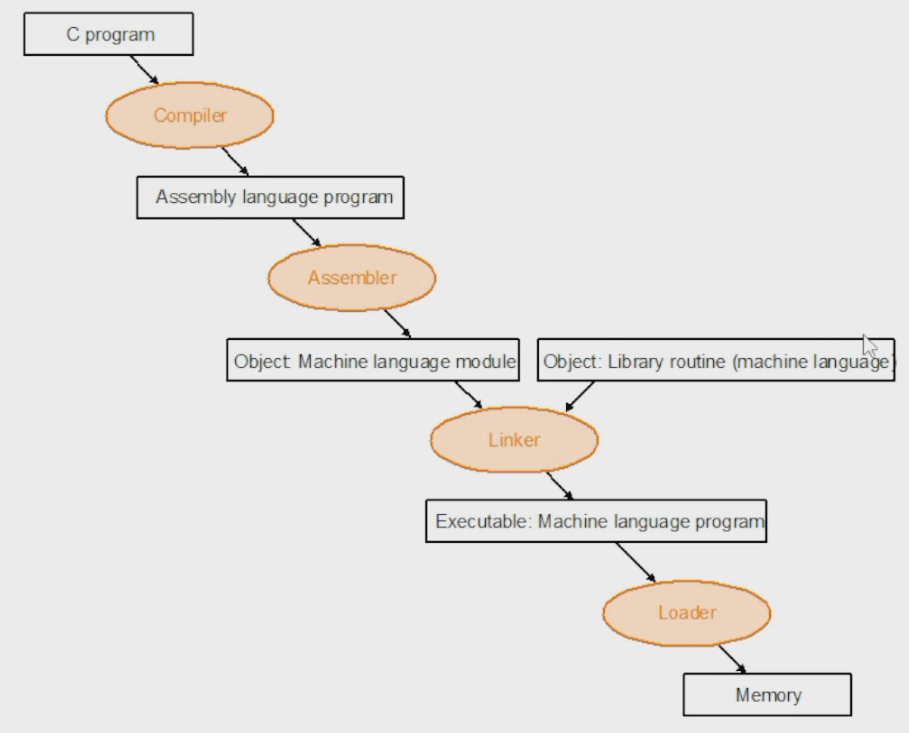
Computer Hardware System
 $$
\text{Computer System} =
\begin{cases}
\text{software}
\ \text{hardware}
\begin{cases}
\text{CPU}
\begin{cases}
\text{Control unit}
\ \text{Datapath}
\begin{cases}
\text{Path: multiplexors}
\ \text{ALU: adder, multiplier}
\ \text{Registers}
\ \dots \dots
\end{cases}
\end{cases}
\ \text{Memory}
\ \text{I/O interface}
\begin{cases}
\text{Input: keyboard}
\ \text{Bidirectional: RS-232, USB}
\ \text{Output: VGA, LCD}
\end{cases}
\end{cases}
\end{cases}
$$
$$
\text{Computer System} =
\begin{cases}
\text{software}
\ \text{hardware}
\begin{cases}
\text{CPU}
\begin{cases}
\text{Control unit}
\ \text{Datapath}
\begin{cases}
\text{Path: multiplexors}
\ \text{ALU: adder, multiplier}
\ \text{Registers}
\ \dots \dots
\end{cases}
\end{cases}
\ \text{Memory}
\ \text{I/O interface}
\begin{cases}
\text{Input: keyboard}
\ \text{Bidirectional: RS-232, USB}
\ \text{Output: VGA, LCD}
\end{cases}
\end{cases}
\end{cases}
$$
Intel CPU 发展历史
-
1971 年,Intel 4004
- 第一个微处理器
- 所有 CPU components 都在 single chip 上
- 位宽只有 4 bits
- 如果需要进行更多位的计算,那么就要用到 SIMD (Single Instruction, Multiple Chips) 技术
-
后来,8008 有了 8 位,是第一个通用微处理器
-
8086 有了 16 位,much more powerful
-
80486 有了
- sophisticated powerful cache
- instruction pipelining
-
Pentium 引入了所谓超标量 (Superscalar) 计算,旨在使用并行性更好地加速计算
- 具体来说,如果你有多个 ALU, FPU,而且若干条指令之间没有依赖关系,那么你就可以同时执行这几条指令
-
Pentium Pro 引入了更多的特性
-
Increased superscalar organization
-
Aggressive register renaming
-
运用虚拟寄存器(虚拟寄存器数量很多,实际的寄存器数量有限)+依赖分析技术,使得寄存器能够发挥出最大能力
-
也就是说,与其
不如
这样,
temp1和temp2就可以并行执行了
-
-
-
branch prediction
-
data flow analysis
-
speculative execution
-
-
Pentium II 的新特性
- MMX 技术:使得图形、视频、音频处理更加高效
-
Pentium III 的新特性
- 3D 浮点运算
-
Pentium 4
- 一些浮点运算和多媒体处理的 enhancements
-
Itanium
- 位宽提升到 64 bits
CPU 性能评估
性能评估的指标

- 对于用户而言,关注的是 response time。Response time 也和软件、外接设备(如鼠标、硬盘等)有关。
- 对于设计者而言,最重要的还是 CPU time,因为 CPU time 只和 CPU 本身有关。
- 对于管理员而言,throughput time 就是总性能/吞吐率。
- 如果所有程序都没有用多线程技术,那么,添加核数不会增加单核的性能,但是可以让服务器同时服务的人数更多,也就是增加了总性能。
CPU time
CPU time 包含了
- User time: 执行用户代码的时间
- Sys time: 执行系统代码的时间
IC (Instrution Count) and CPI (Clock per Instruction)

如上图所示,对于一个程序而言,它有时钟周期数和 CPU 时间两个性能指标。前者和程序指令数以及 CPI 有关,而后者还跟 Clock Rate 有关。
提升 Clock Rate,未必能够提升整体性能。如果你将 Clock Rate 提升一倍,那么,可能一个时钟周期就无法完成一个算术运算,从而你需要两个时钟周期去完成,总时间并没有缩短(甚至可能反而增加)。
对于计算机组成而言,我们的主要目的就是:减少 CPI。
影响性能的因素

CPU 性能的瓶颈
主要有三个
- 内存速度跟不上 CPU 速度
- 单位面积功耗增大,散热问题
- 同时,功耗增加时快于 CPU 单核性能增加的。也就是说,性能功耗比随着性能、功耗的增加而增加。
- 摩尔定律受物理规律影响,面临失效
因此,我们需要用到多核并行技术。并行技术,整体来说,有三种:
- Instruction-Level Parallelism (ILP): This form of TLP focuses on executing multiple instructions from a single thread in parallel. Techniques such as pipelining and superscalar architectures fall under this category.
- Data-Level Parallelism (DLP): DLP involves executing the same operation on multiple data elements simultaneously, often seen in SIMD (Single Instruction, Multiple Data) architectures.
- Task-Level Parallelism (TLP): TLP refers to executing multiple independent threads concurrently. This is particularly relevant in today’s context, as it aligns with the trend of increasing processor core counts.
其中,ILP 的潜能基本上已经无法挖掘了(i.e. 即使有无限台计算机,你也无法在一瞬间执行完一个程序,因为前后代码的依赖关系复杂)。
我们现在的优化主要靠 DLP,比如 MapReduce;以及 TLP,也就是将一个进程划分为独立的多个线程同时执行。