Lec 2: Image Classification¶
Challenges¶
Take cat classification (the images are chosen either between cats and other animals, or between different breeds of cats)
-
Semantic Gap: There's no obvious way to convert the RGB map into the semantically meaningful category label of cat
-
Viewpoint Variation: All pixels change (dramatically) when the camera moves!
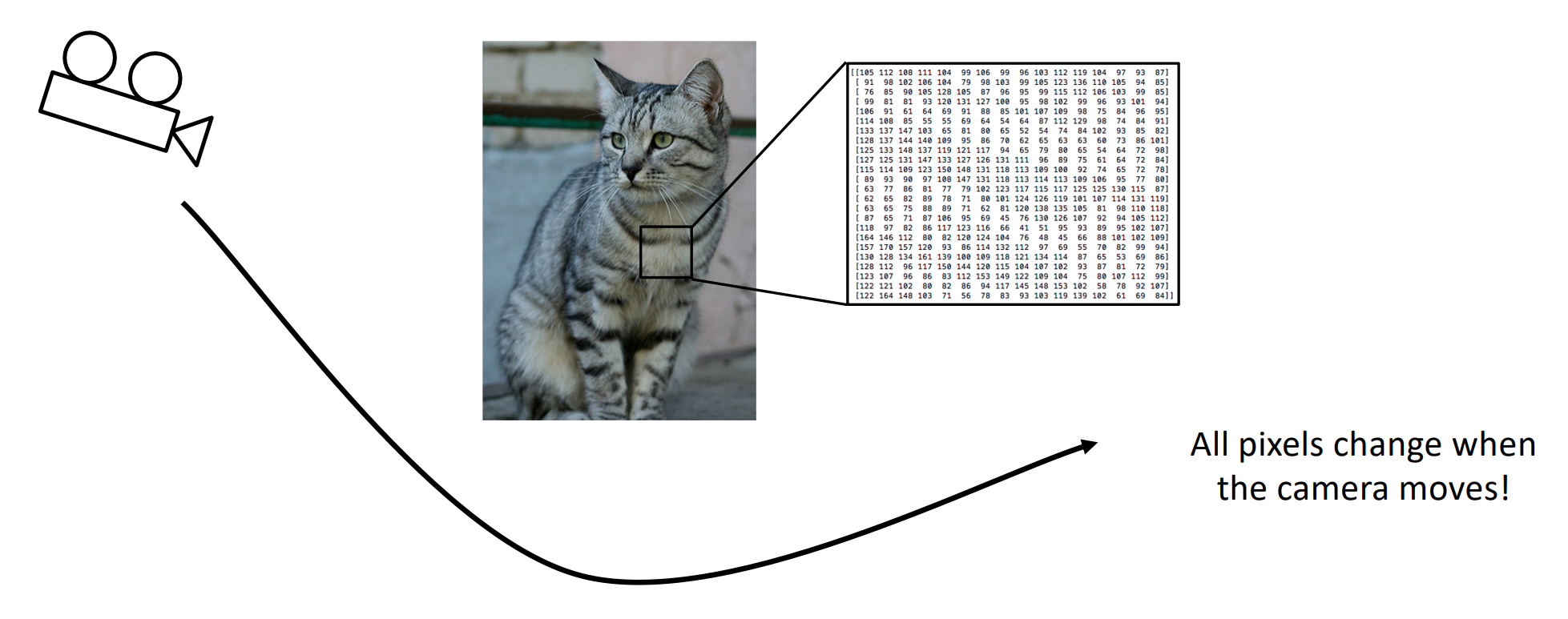
-
Intraclass Variation: Different breeds of cats have distinct RGB map. But we must find the common feature in them.

-
Fine-Grained Categories: Different breeds of cats are still cats, so have similar features as well. We must extract more detailed features to distinguish them.

-
Background Clutter: Sometimes, the images we want to recognize somehow blend into the background

-
Illumination Changes & Deformation & Occlusion (i.e. The Object is Blocked By Something):



- So, actually, the animal under a cushion might be a racoon. However, our common sense tell us that
- cats are likely to appear in homes
- cats can sometimes hide under cushions
- racoons are very unlikely to appear in homes
- So, actually, the animal under a cushion might be a racoon. However, our common sense tell us that
Naive Approaches¶
We can use nearest neighbor approach.
That is,
- we use \(L^1\) norm to calculate the "distance" between the test image and all training images,
- find the training image that has the smallest distance, and
- give the prediction that the test image is of the same category as the nearest training image.
To enhance the robustness, we might use the nearest k-th neighbor.
Actually, k-th nearest neighbor algorithm is practical if you choose the right metric / right data.
For example,
-
considering this arXiv paper recommendation system. It uses a metric called tf-idf.
-
Also, using feature vectors instead of raw pixels in KNN can make good predictions.
Set Hyperparameters¶
Always divide your dataset to three disjoint parts:
- training set: where you get your model
- validation set: where you test your model on and tune your hyperparameters (e.g. the \(k\) in \(k\)-th nearest neighbors and the metric we use)
- NOTE: the only purpose of the validation set is to let you compare the performance of models based on different hyperparameters.
- test set: you can only use it to test once on your model. If the result is bad, you fucked you; otherwise, congratulations!
Also, you can do cross validation. That is, split data into folds, try each fold as validation and average the results
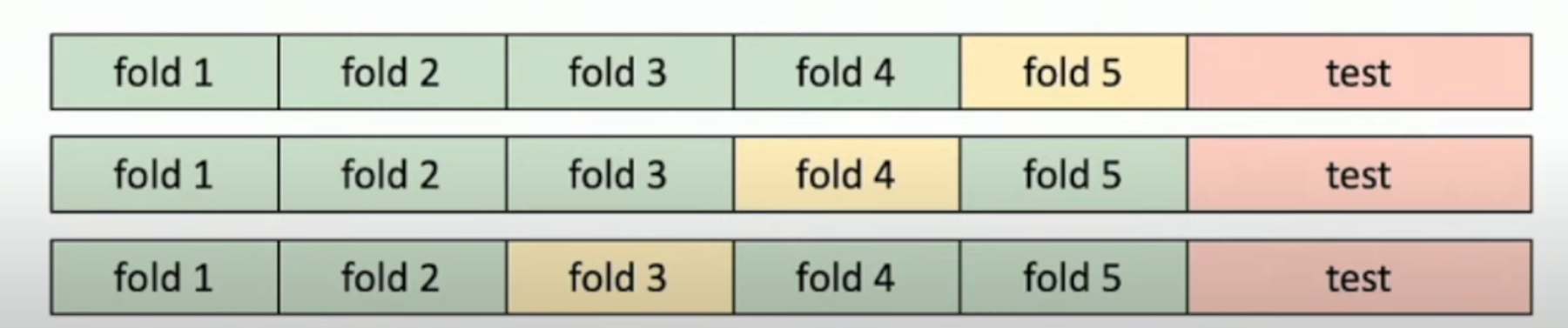
- We do this, because averaging means better than worst case.
Summary¶
- In Image classification we start with a training set of images and labels, and must predict labels on the test set.
- Image classification is challenging due to the semantic gap: we need invariance to occlusion, deformation, lighting, intraclass variation, etc
- Image classification is a building block for other vision tasks
- The K-Nearest Neighbors classifier predicts labels based on nearest training examples
- Distance metric and K are hyperparameters
- Choose hyperparameters using the validation set; only run on the test set once at the very end!