Lec 3: Inverted File Index¶
Introduction¶
倒排索引,可以使用邻接矩阵。
- 列记录的是单词出现在了哪一篇文章中
- 行记录的是单词本身
对于每一个 word,其行向量被称作 Boolean query。
但是,这样做,如果文章很多,那么存储量就会很大。
不过,这个矩阵是稀疏的,因此可以矩阵稀疏化,也就是变成邻接表(具体地,是横向列表,称为 posting list)。
我们不仅可以记录文章数,还可以记录 frequency。
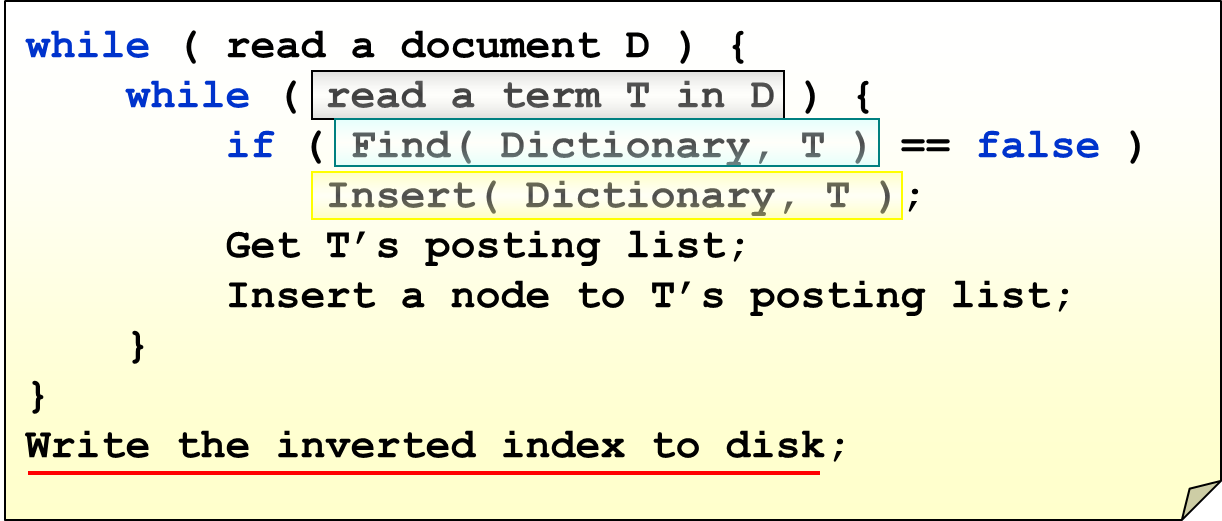
How to parse?¶
如何去掉冗余的词语(我们不仅要存词,还有存 phrases,因此可能会存很多东西)?
- 去掉 a, the, is(停留词过滤)
- 去掉时态(词干分析)
不过,这两种方法,在 NLP 领域,并不太好,因为 "say" 和 "saying" 差别很大,而 "The Who" 和 "Who" 的意思差别也很大(前者是专有名词, 是一个 British rock band)。因此,现实中,我们经常使用 byte-pair-encoding。
How to find?¶
我们可以使用
- 树:B+ Tree, Trie, etc
- 哈希表
来存储。
哈希表虽然快,但是区间查询不友好;而 B+ Tree 对区间查询十分友好。
Distributed Indexing¶
互联网大数据时代,我们无法将所有 index 存在一台设备上。
我们有两个 solutions。

后者的好处:
- 可扩展性强:因为文章是时刻增加的,而单词一般是不变的。如果用前者,随着时间的推移,每一台机器上储存的文件会大量增加。
- 健壮性好:即使有几个机器坏了,查询的单词也不会因此而消失(顶多只会减少出现的文章数)
前者的好处:
- 并行性会好一些
Dynamic Indexing¶
文章的添加和删除是在线、动态的,但是更改数据库是非常耗时的。
因此,我们会使用 main index(做了持久化处理,写的效率比较低,读的速度很快)以及 auxiliary index(表示尚未加入的改变)。
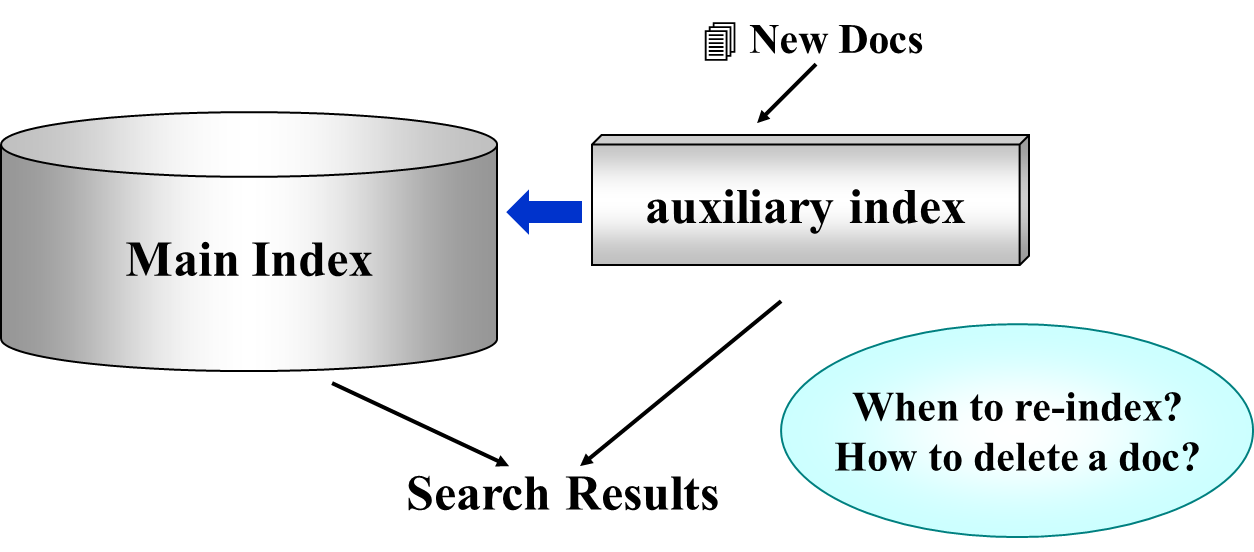
When to re-index? 一般情况下,可能会隔一段固定的时间,在机器比较空闲的时候,进行 re-index。
How to delete a doc? 很多情况下,我们会采用持久化数据结构,也就是逻辑上删除了,但是实际上快照还保存在机器上。
Compression¶
Compression 的流程,就是
- 首先删除介词
- 由于单词不定长,因此我们就将单词连续储存在一个数组内
- 然后,我们使用 posting list 来对其每个单词的起始位置(便于区间查找,如下图)
- 由于单词数组可能会非常长,因此我们为了使用 32 位无符号整型存储(或者其它的一个固定大小的整型),我们使用差分进行存储
- 实际上,除了存储单词的起始位置,我们还可以存储单词的横向列表(如下图,下图的 posting id 存的是 doc id)

Thresholding¶
如何对 document 的重要性进行排序?
Page Rank¶
我们可以将文章之间的关系变成图,然后用特殊方法构建一个 Markov Chain,计算终态概率,当作 weight,然后进行排序。
缺点:
- 无法使用 Boolean logic 进行查询
- 比如查询 Apple Store 的时候,Apple 前十个肯定和水果有关,Store 前十个可能和打折等等有关,但是均不同时含有 Apple + Store,因此找不出来任何 Apple Store 的结果
- Can miss some relevant documents due to truncation
Query¶
我们用词语的频率去卡 percentage。
也就是,如果检索的是多个单词的并集,那么,我们就会使用所有文章中出现频次最低的前 \(n\%\) 的单词来检索+取并集,而剩下的单词就不管了。这样同时保证了搜索的准确性和(适当的)模糊性。
In pratice,我们往往先做 query,然后进行 page rank。